
DBMS에서 지원하는 데이터 타입에서 살펴봤듯이 각종 DBMS가 지원하는 대표적인 문자형 데이터 타입에는 고정 길이 문자형을 표현하는 'CHAR'와 가변 길이 문자형을 표현하는 'VARCHAR'1가 있습니다. 필자는 고정 길이와 가변 길이로 구분한 이유가 궁금했습니다. 데이터 타입을 고정 길이와 가변 길이 형태로 구분한 이유가 무엇일까요?
ANSI SQL 표준화 작업 과정 중 데이터전문가들이 검토한 결과로 데이터베이스에서 문자형을 표현하는 데이터 타입을 고정/가변 길이로 구분할 필요성이 있었던 것 같습니다. 아마도 데이터 표현과 데이터 관리의 명확성 때문에 위와 같이 구분한 것 아닐까요? 데이터 타입을 명확히 구분하는 것이 해당 속성의 데이터 특성을 이해하는데 훨씬 효율적일 것입니다. 하지만 데이터 설계를 완벽하게 수행하면 문제가 없습니다만, Oracle에서 하나 또는 유사한 속성을 'CHAR'와 'VARCHAR2'로 혼재해서 사용하면 의도치 않은 결과를 초래할 수 있습니다.
CHAR와 VARCHAR2
CHAR
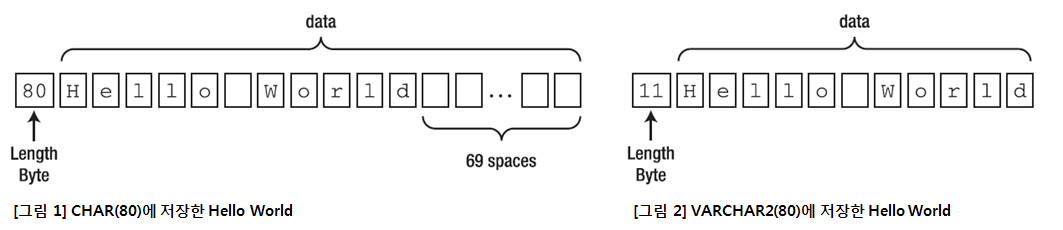
Oracle에서 고정 길이 문자열을 표현하는 문자 타입입니다. CHAR(80)으로 설정한 속성에 'Hello World'를 저장한 결과는 [그림 1]과 같습니다. 특이한 점은 데이터 앞 부분에 속성의 길이에 따라 1~3바이트의 길이 필드를 가진다는 점입니다.
데이터베이스를 사용하는 대다수 사용자가 고정 길이 문자열(예를 들어, 주민등록번호나 사번 등을 문자타입으로 저장할 경우)을 사용할 때, 'CHAR'를 사용하는 것이 유리하다고 알고 있습니다. 결론부터 말씀드리면 Oracle에서는 이런 상황에서 'VARCHAR2'를 사용하는 것과 비교했을 때 전혀 유리하지 않습니다.
VARCHAR2
'VARCHAR2'는 Oracle에서 가변 길이 문자열을 표현하는 문자 타입입니다. VARCHAR2(80)으로 설정한 속성에 'Hello World'를 저장한 결과는 [그림 2]와 같습니다. 'CHAR'와 마찬가지로 데이터 앞 부분에 속성의 길이에 따라 1~3바이트의 길이 필드를 가집니다.
11바이트 길이의 'Hello World'를 저장한 경우, CHAR(80)에서는 11바이트의 요구 문자열이 저장됩니다. 그리고 나머지 69바이트가 공백 데이터로 채워지는 것을 확인할 수 있습니다. 결과적으로 이와 같은 상황에서 69바이트가 낭비된다고 볼 수 있습니다. 반면에 VARCHAR2(80)에서는 11바이트의 공간만 사용하는 것을 확인할 수 있습니다.
병행 사용할 때의 문제점
Oracle의 전문가로 통하는 Tomas Kyte는 그의 저서 <Expert Oracle Database Architecture>에서 다음과 같은 말을 했습니다. '개인적으로 VARCHAR2나 NVARCHAR2 두 가지 문자 데이터 타입만 사용하면 된다고 생각한다. 나는 어떤 어플리케이션에서도 CHAR 타입을 사용한 적이 없다'. 굉장히 자극적인 메시지입니다만, Tomas Kyte가 이처럼 이야기 한 여러 가지 이유가 있습니다.
가장 간단한 이유는 저장 공간의 비효율성입니다. 현실적으로 정확한 길이를 가지는 문자열 속성이 많지 않으며, CHAR형으로 지정하면 유연성이 심각하게 나빠지게 됩니다. 다음으로 Oracle 내부 구현 문제로 묵시적 형 변환이 발생합니다. 묵시적 형 변환 문제로 말미암아 의도치 않은 결과를 얻을 수 있으며, 질의 성능의 저하를 발생하는 원인이 됩니다.
다음 단락부터 저장 공간의 비효율성을 제외하고, 묵시적 형 변환이 발생하는 상황과 질의 성능이 나빠지는 경우를 조금 더 자세하게 알아보겠습니다.
묵시적 형 변환
형 변환은 데이터 타입을 다른 형태로 변경하는 것입니다. 대표적인 형 변환으로 명시적 형 변환과 묵시적 형 변환이 있습니다. 명시적 형 변환은 사용자가 직접 데이터 타입을 변경하는 것이며, 묵시적 형 변환은 시스템 자체의 고유 로직에 따라 자동으로 데이터 타입을 변경하는 것입니다. 이때, 문제가 되는 것은 묵시적 형 변환입니다. 왜냐하면, 시스템의 형 변환 로직을 정확히 모르는 경우에 의도하지 않은 문제를 발생할 소지가 있기 때문입니다.
Oracle의 묵시적 형 변환 규칙을 간단하게 살펴보겠습니다. Oracle의 묵시적 형 변환 규칙에 대한 더 자세한 내용은 Oracle의 공식 문서를 참조하시기 바랍니다.
- 숫자 타입은 가장 큰 (precision, scale) 타입으로 변경
- 문자 타입과 숫자 타입을 비교할 때, 문자 타입을 숫자 타입으로 변환
- 날짜 타입과 문자 타입을 비교할 때, 문자 타입을 날짜 타입으로 변환
- 날짜 타입과 숫자 타입을 비교할 때, 숫자 타입을 날짜 타입으로 변환(단, 날짜와 날짜를 연산하면 숫자 타입으로 반환)
- 문자열 결합(Concatenation)을 할 때, 비문자 타입을 문자 타입으로 변환
- 문자 타입과 비문자 타입을 산술연산하면, 숫자(NUMBER) 타입으로 변경
- CHAR와 VARCHAR2, NCHAR와 NVARCHAR2를 비교할 때, 다음 공식에 따라 형 변환
To CHAR To VARCHAR2 To NCHAR To NVARCHAR2 From CHAR VARCHAR2 NCHAR NVARCHAR2 From VARCHAR2 VARCHAR2 NVARCHAR2 NVARCHAR2 From NCHAR NCHAR NCHAR NVARCHAR2 From NVARCHAR2 NVARCHAR2 NVARCHAR2 NVARCHAR2
이 표를 해석하는 방법은 다음과 같습니다. 쉽게 From A To B 형식으로 이해를 하시면 됩니다. 예를 들어, From CHAR To VARCHAR2는 VARCHAR2로 묵시적 형 변환이 발생하는 것입니다.
Example: CHAR와 VARCHAR2의 병행 사용
프로젝트를 진행하다 보면, 데이터 모델링을 명확하게 수행하지 않은 환경에서 같은 계열의 속성(유사한 속성)간 다수의 도메인 타입을 설정하는 상황을 만날 수 있습니다. 예를 들면, A 엔터티에서 회사이름을 CHAR로 설정하고, B 엔터티에서는 VARCHAR2로 설정한 경우가 있을 수 있습니다. 간단한 예제를 활용하여 CHAR와 VARCHAR2 타입으로 설정된 값을 비교해 보겠습니다.
먼저 간단하게 테이블을 하나 생성(T)하고, 기본 데이터를 삽입('Oracle')합니다.
CREATE TABLE T (
char_type CHAR(10),
varchar2_type VARCHAR2(10)
);
INSERT INTO T VALUES ( 'Oracle', 'Oracle');T 테이블을 생성하고, 각 컬럼에 'Oracle'을 삽입했습니다. 여기에서 질문을 하나 하겠습니다. 위 2개의 속성을 동등 비교한 결과를 예측해 보십시오. 두 속성의 값은 동등할까요? 결론적으로 위 두 속성은 값은 같지 않습니다. 왜냐하면, char_type에 저장된 'Oracle'은 기본 6자리에 추가로 4개의 공백 문자가 결합된 형태로 저장되기 때문입니다. 그러므로 사용자가 생각하는 "char_type = varchar2_type"을 만족하지 못하고, "char_type > varchar2_type"을 만족합니다.
SELECT * FROM T WHERE char_type = varchar2_type;
SELECT * FROM T WHERE char_type > varchar2_type;
하지만 위의 결과는 일반적으로 사용자가 원하는 결과가 아닙니다. 사용자가 원하는 결과를 얻기 위해서는 어떻게 해야 할까요? 매우 비효율적이지만, Oracle에서 제공하는 내장 함수(trim(), rpad() 등)를 사용하여 공백을 제거한 후 비교하는 것입니다.
SELECT * FROM T WHERE trim(char_type) = varchar2_type;
SELECT * FROM T WHERE char_type = rpad(varchar2_type, 10);
앞에서 살펴본 것과 같이, Oracle에서 CHAR와 VARCHAR2를 함께 사용하는 경우 사용자가 의도치 않은 문제를 발생하게 됩니다. 즉, 명확하게 이해하지 못하고 사용하면, 예상하지 못한 결과를 얻을 수 있습니다. 이 예제는 간단한 경우이지만, 실제 운영하는 환경에서 이와 같은 사소한 문제로 치명적인 문제(의도하지 않은 결과)를 발생할 수 있습니다.
또한, 인덱스를 사용하지 못하는 상황을 만날 수 있습니다. 위 예제를 이용하여 설명하면, Oracle 내장 함수인 trim()을 사용할 경우 인덱스를 활용할 수 없습니다. 인덱스를 사용하려면, 위 예제의 두 번째 경우인 rpad()를 사용하는 형태로 질의를 작성하거나, 함수기반 인덱스(FBI)를 활용하면 인덱스를 사용할 수 있습니다.
마치면서
지금까지 대표적인 상용 DBMS인 Oracle에서 'CHAR' 데이터 타입과 'VARCHAR2' 데이터 타입을 함께 사용할 때, 의도치 않게 발생하는 문제점에 대해 살펴봤습니다. 이 문제를 해결하는 가장 간단한 방법은 무엇일까요? 문자형 데이터 타입을 설계할 때, 'CHAR' 데이터 타입을 사용하지 말고, 의도적으로 'VARCHAR2' 데이터 타입을 사용하는 것입니다. 왜냐하면, 최악의 경우 'VARCHAR2'와 'CHAR'는 동등하기 때문입니다.
References
Thomas Kyte, Expert Oracle Database Architecture
http://expo.daydic.com/18
http://groovysunday.tistory.com/41
- Oracle의 경우에는 VARCHAR2. [본문으로]